Pre- and post work of an SAP System refresh

Veröffentlicht von Shortcut IT in Sc4SAP · 26 Juni 2023
Tags: SAP automation;SAP Systemkopie;SAP system copy;SAP system refresh;R3trans
Tags: SAP automation;SAP Systemkopie;SAP system copy;SAP system refresh;R3trans
It is a recurring task for the SAP Basis: the data of the quality and test systems become outdated, are thus less and less useful and must therefore be periodically updated with data from the productive system. For the SAP Basis, this is a high effort, and also under time pressure. After all, the systems should be available again quickly. With "Shortcut for SAP systems", most of the pre- and post-processing can be automated.
There is a lot of information in the web, but... a lot of it seems a bit pieced together. If you compare the several How-To-Do lists on the websites, you will find a lot of overlap, but there are also activities that can be found in one list but not in the other. And there are still tasks like "Take a screenshot of ..." on the lists for the pre-work, and - consequently - tasks to be done manually in the post-processing to reconfigure the system according to the taken screenshots.
This is something that definitely needs to be impoved. We want to get rid of manual activities like taking screenshots and repeating manual configurations. Read here how to achieve this.
In this article I would like to point to the "PCA" tool and how we can use it. "PCA" stands for "Post Copy Automation" and was developed by SAP for supporting system copies / refreshes. However, you need a "SAP Landscape Virtualization Management (LVM), enterprise edition license" (see SAP note 1589175) to use it. If this is given, you may follow the installation guide and use the Task Manager (transaction STC01) for doing the pre work and the post work.
If you do not have the required license, you will see in this article, how information from the PCA tool can be used and a lot of pre- and post work can be done using "Shortcut for SAP systems".
The general approach to pre- and post-processing - both in the PCA tool and in third-party solutions such as Libelle System Copy, BlueCopy, etc. - is as follows:
1) back up the system-specific configuration data of the target system of the copy before overwriting or replacing the database contents.
2) and restore it after the system refresh on the basis of the backed-up data.
In many how-to's that you can find on the web, you are advised to create screenshots and then configure the system based on the created screenshots. This requires a lot of manual work both in preparation and in post-processing, with all the resulting disadvantages, e.g.:
- If something is forgotten during preparation - e.g. a screenshot - it may not be possible to correct it during the post processing.
- Manual activities are prone to errors.
- The processing times for manual activities are longer than for restoring saved data.
- The manual activities may have to be carried out at "inconvenient" working times, which may again increase the susceptibility to errors.
Therefore, the approach with manual activities should be left behind as far as possible and as much of the pre- and post-processing as possible should be done by backup / restore.
Let's see how we can achieve this. First, let's see what the PCA tool can do for us. Hmm... I already wrote that we need a licence for this, so what else can we expect here? With the PCA tool we can get the information of the tables to be backed up (and restored after the system refresh). Even if the license may not be there and the configuration of the PCA tool requires additional effort, we can use it for getting the information about the relevant tables.
There is a report SCTC_LIST_TABLES available in every(?) SAP NetWeaver system, that is useful for for showing the relevant tables.

Ok, there are some values to be given as input: a choice between "Refresh" and "Data Cleanup" and an obligatory "Component". Unfortunately there is no F4 list available for the "Component". However, to shorten this: the execution of this report causes some problems. We do not know the "Component" up to now, and even if we would (try "RFC" for example), we would be faced with an error message:
Despite the program is not running, we can still use it for getting the information. A look into the source code shows that the information about the relevant components is hard-coded in function module SCTC_GET_ALL_COMPONENTS and from there the information about the assigned tables is in Include SCTC_SC_INCL_COMPONENTS.
You can use this program, which is a modified copy of it. You can find it also supplied with our product in the folder 'ABAPs' (file 'ShowPCATables.txt'). Just create it in the customer name space of the development system. Most of the PCA tables are hard-coded in ABAP source codes, some are determined from the TADIR table (R3TR TABL from (also hard-coded) packages), you do not need to forward the program to the Quality or Productive system - the result is the same as long as the release on the Dev, QA and Prod system is the same.
The selection screen is similar to the one from SAP's program SCTC_LIST_TABLES. But you do not have to specify the 'Component'.

So, what is this "Refresh" and "Data Cleanup" about?
- The "Refresh" option belongs to tables that are to be exported in front of the system refresh and to be imported after the system refresh.
- The "Data Cleanup" option belongs to tables that are to be emptied after the system refresh, but before importing the saved data again. For example, the tables containing the printers are part of the "Data Cleanup". Without emptying these tables, the printers from the source system would additionally be available after the sytem refresh. This may not be desirable as there could be a separation between the printers used in the productive system and those used in the quality system.
Ok, now let's execute the program with the "Refresh" option - to see the tables that should be backed up before and restored after the system refresh:

You will find in the list all components and their tables, that are handled in the PCA tool: ALE stuff, Batch Input, SAP Office, printer, operation modes etc. - lots of stuff that possibly you are already aware of and dealed with it more or less cumbersome by taking screenshots before and repeating the configuration tasks after the system refresh. And maybe there is some stuff you were not aware of in the past.
In addition to the original SAP program SCTC_LIST_TABLES you will also find some information about the table size, the amount of rows, whether the table is client dependent or not and a button enabling you to jump to the Data Dictionary information for the tables (SE11).
Ok, so now we have the information about the components and their tables which are worth to be managed in the context of a system refresh. How can we use this information now?
Have a look at the "XML file" button at the top of the list. Such a small button, but it can save us soooo much work.

Let's try it. A popup appears:

We choose the "Sys.refresh-Export" option. As this article is about SAP system refresh, first we have to export data in front of the system refresh, therefore we follow the sequence.
Another popup appears:

Table NRIV contains the number ranges. This table is listed more than once and is therefore part of multiple components. Let's get back to the list and filter it for table NRIV:
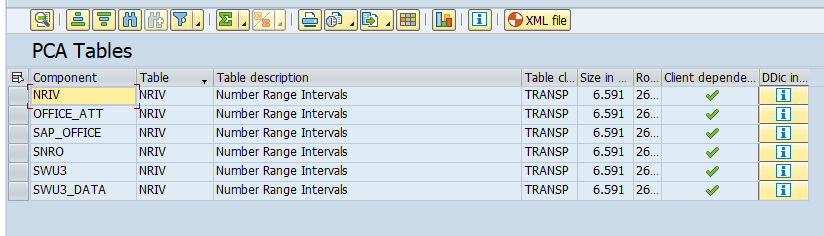
For components OFFICE_ATT, SAP_OFFICE, SWU3 and SWU3_DATA only parts of the table would be considered. For components SNRO and NRIV all records of the NRIV table would be considered.
Our aim is to get recent data of the productive system via system refresh - including all the business documents, where lots of them have a document number, received from the number range method based on the NRIV table. If we save the whole NRIV table - the last given number for each number range object is part of it - and restore it after the system refresh, we will run into problems when it is about creating new documents. Assuming that on our Quality system currently there are less documents than on the Productive system, the last given number in the NRIV table is already occupied.
In a nutshell: leave out the components SNRO and NRIV and consider the NRIV table for the other components only.

Next attempt for generating the XML file.
After clicking on the button "Sys.refresh-Export" the warning popup does not appear anymore. Now we are asked for some paths.

First path is for the destination of the files containing the exported data. I prefer to have a dedicated directory for the files from the system refresh, so I created a directory systemrefresh in DIR_HOME.
The second path is about a temp directory on your frontend. Tables where only a selective amount of data is to be processed (like NRIV, DOKIL and TADIR) can (currently) not processed with the "Process table data using R3trans" function, so for these functions the "Download / upload table data" function will be used. As it is about downloading data from the SAP system, the frontend is involved. However, finally all data will be stored in the directory on the SAP server, so this is only a temporary storage.
Ok, so my input for this popup is this:

Now we are asked for a directory and filename of the XML file:

After specifying folder and filename another information comes up:

There is a difference of 'Total tables' to 'Distinct tables'. This is because some tables are listed in more than one component (e.g. the components ARCHIVE, ARCHIVE_ADK and ARCHIVE_CUST have some intersections regarding their tables, same is for components CRM, CRMINERP, PI_BASIS_CRM and some more).
Let's have a look into the file:

For each component we find a <Task> in the XML file, containing all the tables from the list to be exported into a file. In most cases R3trans is used, in some cases the "Download / upload table data" function is used. When the "Download / upload table data" is used for a table, a corresponding <UploadFile> task exists with the given SAP directory as target.
There is only one modification of the XML file needed.

As some data is to be downloaded, a connection using a user with dialog capabilities is necessary.
After specifying a suitable connection in the XML file, we call the command line tool for processing it.

During the execution of the tasks you can have a look into the specified target directory and see the files being created:

After few minutes (which is of course depending on the amount of data in your system) the execution finished.
Having again a look into AL11 we find for every R3trans file also a log file. Let's have a look into one of them:

Ok, it worked. With this we have done the pre work of the system refresh.
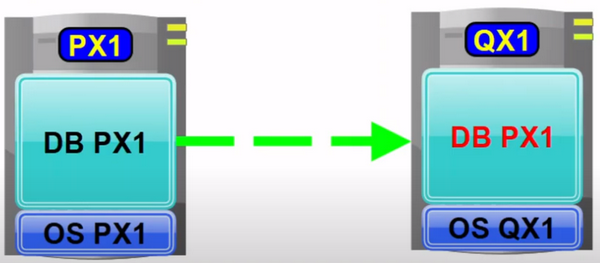
Now let's make a jump to the time when the systems database is overwritten with the one from the source system. As you know some data has to be adjusted - this is all the stuff with the manual reconfiguration of lots of settings like SAP Connect, the server groups, CCMS configuration, TMS configuration, logical paths and files, the SAP license, logon groups, operation modes etc. etc. etc.
We are going to do this by restoring the saved data. All of the mentioned topics are covered in the tables we saved in front of the system refresh - so by restoring these data we will have the same status in the overwritten system as before.
As mentioned above, there is a "Data cleanup" task to be executed in front of the restore. Let's go back to our program and generate an XML file for this.

After clicking the "Execute" button we receive the list and again we use the "XML file" button and specify the system on the SAP server.

As it is about deletion of data no data files will be created. The directory on the SAP server is only for the log files.
After this we are asked again about directory and filename of the XML file.

After this the creation of the XML file is done in less than a second. Again a popup with some information about the content of the XML file comes up:

There is a hint: SRT_MONILOG_VIEW (is not a table)
That is correct, it is a view, using table SRT_MONILOG_DATA. This table is part of the "Refresh" set and also in the "Data cleanup" set, so it is exported, will be emptied and is to be imported again. By doing this with the table also the view will have the same data as before - it is not clear to me why the PCA tool lists this view here.
The created XML file looks similar to the one created for the Export. The R3trans command has changed from <Export> to <Remove> and instead of a <ServerFile> we now have a <ServerLogFile> (as it is about deletion of data, we do not have a data file).

After adjusting the connection (line 3) I start again the command line tool.

Ooops, return code 4. A warning. As we do this the first time, we should find the reason and see if something has gone wrong.
The command line tool updates the XML file after processing it. So instead of scrolling in the console it is more comfortable to search for details in the XML file.

The log file shows the reason of it:

Here a warning was given because all tables were already empty. R3trans had nothing to do, so it quitted with a warning.
There were some more return codes 4, and all of them had the same reason.
If you have a look into the SAP system, you will find some impacts of the data cleanup. This is STMS after deleting some TMS data:

Also some other areas look empty: batch input session (SM35), shortdumps (ST22), ...
The Data cleanup part took ~1 minute only on the system. As it is about deletion of data and the amount of tables is smaller than for the previously done 'Export' part, also the needed time is less.
Now let's do the last step (and the most exciting of all): importing the saved data again. Coming back to our XML file generation tool: let's use the "Refresh" option again and create an XML file. As we filtered out the components NRIV and SNRO for the export, we do the same now (if you forget it, you will be faced again with the warning popup).


We store the file near to the others and name it accordingly:

Again the generation of the XML file is done within a second and we see some information about the content of the XML file.

The generated XML file looks very similar to the one generated for the Export. Some task types changed the direction: <Export> has turned to <Import>, <DownloadTableData> to <UploadTableData> and <UploadFile> to <DownloadFile>. After specifying the connection in line 3 the XML file is ready for execution.
Now start the command line tool for processing the XML file. It takes more time than the Export.

Again there are warnings, so have a look into the log files.
Now we find 2 warnings in the logs:

The first warning "Selective import specified" is because of the SELECT statements for each table that is stored in the file, and the second warning is because R3trans notices that the file used for import has its origin on the same system. Yes, that is exactly what we did - export and import on the same system.
We can ignore these warnings, they are the same for every task.
The import tasks needed significantly more time than the export tasks: ~27 minutes on my small system. This is because updating the tables in general needs more time than just reading the data. Beside others indexes are to be considered, rollback segments are to be managed by the database etc.
The log files look a little bit different from the 'export' ones, pointing to the fact that it is here about update / insertion instead of simple reading:

Let's have a look into the system now. The TMS looks fine again, also the batch input sessions and the SAP Connect settings in transaction SCOT look like before the system refresh.
All the configuration settings are the same as before the system refresh. This is a huuuuge gain of saved time in comparison to do the pre and post processing manually, using screenshots and do lots of configuration stuff to get the status of the system back as it was before the system refresh. And, if you up to now used a documentation with lots of manual activities, I guess dealing with system specific data using the above described method is much more complete than doing this using your documentation, isn't it?

Once you have finished the adjustment of the XML files for pre-work (Export) and post-work (Data cleanup and Import), you can use it easily to do the pre- and post-processing as often as you like - so, if there is the demand to do the system refresh every month or even every week, there is no need to be afraid of the previously huge amount of work anymore! At the end it is about 3 calls of the command line tool:
sc4sapcmd "...SystemRefresh_Prework.xml"sc4sapcmd "...SystemRefresh_Postwork_Part1_Data_Cleanup.xml"sc4sapcmd "...SystemRefresh_Postwork_Part2_Import.xml"
As this is working on OS level, you can also easily schedule these tasks or integrate it in already existing automation solutions. Have your weekends been messed up for this in the past? That can now come to an end.
Finally I would like to give some hints on this topic:
- Of course it is on you to decide which components and tables are to be considered. If you do not want to deal with the full scope of data, you can filter the list of the program Z_SHOW_PCA_TABLES and / or de-select tables. Possibly you want to get the batch input sessions from the source system, then just leave out the BATCH_INPUT component for Export, Data Cleanup and Import. Just take the list of the program, think about it, discuss and agree with your colleagues and/or the user department, which components are to be considered and which not.
Filter and selection in the list of Z_SHOW_PCA_TABLES will be considered when generating the XML file - means, components and tables that are filtered out or de-selected will not be considered in the generation of the XML file. Certainly, you can also modify the XML file in a text editor and take out some tasks or add others. - In the 'xml' folder of "Shortcut for SAP systems" you will find XML examples for pre- and post work of a system refresh. Have a look into it, they show some additions: in the pre-work locking and kicking out of users is integrated as well as suspending batch jobs in front of data saving. And in addition to the tables shown by the PCA tool, also the ALV layouts are considered. Consequently this is also implemented in the post-processing example.So you can inform the users about the upcoming system refresh and schedule the command line tool with the pre-processing XML file e.g. for Friday evening - no need to do it on your own and stay in the office. Turn this into an automatism.
- If you want to speed up the process (maybe especially the import, which consumes the most time), you can split the XML file in smaller pieces. Each file needs to contain the <ExecutionChain>...</ExecutionChain> tag and the information about the connection. For example, instead of one XML file containing ~80 R3trans tasks you can create 4 XML files, each file containing ~20 R3trans tasks, and run 4 instances of the command line tool in parallel - or even more. Calling the command line tool occupies a DIA work process in the SAP system. During the pre and post processing of a system refresh nearly all existing DIA WP's can be used by you, so do not hesitate to make use of it.
- By default also the users are considered in the PCA tables. If you do not want this, leave out the USERS component. For some reasons it makes sense to receive all users and their role assignments from the source system, just like you receive material master data, FI documents etc. from the source system - finally, it is the aim of a system refresh to get data close to the productive environment.
However, the system users have to be the same as before the system refresh, otherwise interfaces would not work anymore. And possibly project teams etc. are also to be kept.
You also have the possibility to keep all users in the target system (by exporting / importing the USERS component) and copy additional users from the source system to the target system with the "Copy user" function.
Have a look at these blog articles regarding this topic:
https://www.shortcut-it.com/blog/index.php?how-to-assign-new-passwords-to-lots-of-usersCopying users and setting passwords can also be done in the XML files, so you no longer have to do this manually either.
Es gibt noch keine Rezension.